This article is about vSAN, its policies, and why they matter. During my time working with vSAN, those who have newly adopted this software defined storage solution often experience issues due to storage policies. Why are these things issues? Generally, people don’t know that policy directly effects IOPS, throughput, and latency on vSAN clusters. Hopefully this article gives people a better understanding regarding this matter and can be used as a reference in the future when discussing such things.
First, I’m going to establish some acronyms so that the data is easier to read.
FTT: Failures to Tolerate. Number of node failures within cluster a vm can sustain and still be functional. Based on the number of nodes in a cluster, with possible values being 1 (3 node min.), 2 (5 node min.), and 3 (7 node min.).
FTM: Fault Tolerance Method. Three possible values assigned to FTM- R1, which is simply replication of an object, R5, which, while referenced as raid is in fact erasure code striping across 3 different nodes (not on disks inside a node) and a parity stripe on a fourth node, and R6, which is again erasure coding, with 4 data stripes and 2 parity stripes across six nodes.
SW: Stripe Width. Unrelated to FTT or FTM, SW dictates how many disks an object is striped in 1MB stripes. Max value 12.
You can learn more about these vSAN policy settings here: https://storagehub.vmware.com/t/vmware-vsan-demonstrations/create-a-vsan-storage-policy/ and here: https://storagehub.vmware.com/t/vmware-vsan-demonstrations/vsan-resilience-and-data-placement/
H: this is the number of Hosts per cluster
DD&C: Deduplication and Compression
The story behind this first set of tests – a customer in the financial sector wanted to see how policies affected IOPs, Throughput, and Latency in vSAN. After running the first two tests we were able to add two hosts to the cluster. Here’s the tests I ran and their HCI Bench information:
| HCI Bench Case Name | HCI Run Definition |
| vdb-8vmdk-100ws-4k-70rdpct-50randompct-2threads-1538686968 | RD=run1; I/O rate: Uncontrolled MAX; elapsed=28800 warmup=600; For loops: None |
| vdb-8vmdk-100ws-4k-70rdpct-50randompct-2threads-1538719096 | RD=run1; I/O rate: Uncontrolled MAX; elapsed=28800 warmup=600; For loops: None |
| vdb-8vmdk-100ws-4k-70rdpct-50randompct-2threads-1539131626 | RD=run1; I/O rate: Uncontrolled MAX; elapsed=28800 warmup=600; For loops: None |
| vdb-4vmdk-100ws-4k-100rdpct-100randompct-4threads-1539299433 | RD=run1; I/O rate: Uncontrolled MAX; elapsed=14400 warmup=600; For loops: None |
| vdb-4vmdk-100ws-4k-100rdpct-100randompct-4threads-1539319933 | RD=run1; I/O rate: Uncontrolled MAX; elapsed=14400 warmup=600; For loops: None |
| vdb-4vmdk-100ws-4k-100rdpct-100randompct-4threads-1539220221 | RD=run1; I/O rate: Uncontrolled MAX; elapsed=14400 warmup=600; For loops: None |
| vdb-4vmdk-100ws-4k-100rdpct-100randompct-4threads-1539237266 | RD=run1; I/O rate: Uncontrolled MAX; elapsed=14400 warmup=600; For loops: None |
And here are the results:

I want to point out in this chart, even though FTT 2 FTM R1 provides more copies to read from, it doesn’t produce more IOPs than FTT 1 FTM R1. Additionally, even though a write load was added, there is a rather marked difference in the FTM R5 and R6 workloads, as is also shown in the Throughput chart below. Note they have the same trending- higher numbers (which are good in IOPs and Throughput) at FTM R1, but lower at R5/R6. I’d like to state for the record that there is absolutely nothing wrong with R5/6 erasure coding. If your workload can operate inside the IOPs and throughput supplied when utilizing erasure coding, it’s a great way to efficiently utilize capacity. However, if you find the performance of your vm with that type of FTM is not acceptable, I suggest an FTM R1. It’s important to draw attention to the SW setting as well. While the effect is more apparent in an FTT2 situation, it’s difficult to tell with these graphs, but I assure you there is a very slight difference in FTT 1 as well, with the number of disks in a diskgroup minutely more productive than the number of disks in a host. In my opinion, if one really needs to eke the very possible last bit of performance from a vm or stateful storage, the way to do it is keep the stripe width at or under the number of disks in a diskgroup while utilizing FTT 1 FTM R1.


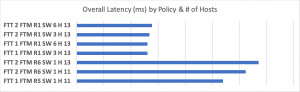
For Latency, we see the opposite trend, which is what we want to see, as lower is better in this case.
While those results alone aren’t much proof by themselves, I was asked by a large agricultural supply chain company to do some testing around SPBM, but the with the additional tasks of checking policies with and without deduplication and compression (DD&C) and measuring rebuild times while utilizing different policies. For these tests I used the following workload at the customer’s direction: block size 16k, R/W ratio of 50/50, 50% random, 24 vms per node with a 200gb working set size and 4 vmdk’s per vm. The cluster was 8 nodes throughout testing, and a default SW of 1 was used. Tests ran for four hours. The policies tested are in the table below:
| POLICY |
| FTT1 FTMR1 NO DD&C |
| FTT2 FTMR1 NO DD&C |
| FTT1 FTMR5 NO DD&C |
| FTT2 FTMR6 NO DD&C |
| FTT1 FTMR1 DD&C |
| FTT2 FTMR1 DD&C |
| FTT1 FTMR5 DD&C |
| FTT2 FTMR6 DD&C |
Here are the results of those test, and specifically I want you to look at the trends based on policy utilized. Notice the same curve pattern with regards to the representation by policy. Also notice what occurs when you combine an FTM R5/6 with deduplication and compression. Personally, I would go with utilizing the FTM of R5/6 on a per vm basis, OR, I would choose to turn on deduplication and compression, not both.
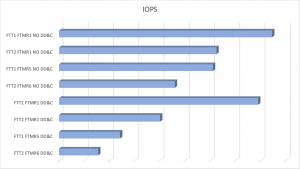
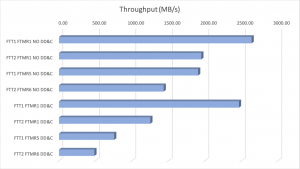
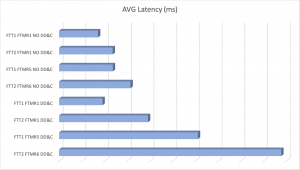
We also see the same trends in latency and the impact of utilizing DD&C with FTM R5/6.
Observing what effect policy has on rebuild times for an 800gb vm. FTT and FTM both altered rebuild time. The policies tested were
| FTT1 FTM R1 DD&C |
| FTT1 FTM R5 DD&C |
| FTT2 FTM R1 DD&C |
And the results:
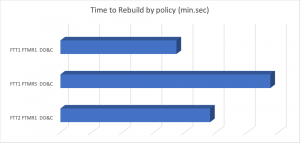
I’m first to admit, it’s not a very large data set. It would be great if someone can prove my viewpoint incorrect. However, in multiple HCI, vSAN, VxRail projects I’ve been involved with, this approach to policy alteration has been successful for me. So please, do your own testing with policies and share your results. I eagerly await them.

VMUG Office
450 Rev Kelly Smith Way, Nashville, TN 37203
[email protected]